


人工知能(AI)は、ソフトウェアの話から、ハードウェアのボトルネックに移行しています。2026年、AI取引は、ASMLのEUV装置やTSMCの先端製造技術からNVIDIAのGPUエコシステム、Broadcomのカスタムシリコン、Marvelのデータセンターインターコネクトまで、大規模なAIインフラを実現する半導体企業によってますます定義されています。ハイパースケーラーの設備投資が7,000億ドルに近づく中、最大の機会はAIチップサプライチェーンの重要な層を支配する少数の企業に集中しています。
同時に、これらの半導体リーダーへのアクセスは、暗号資産ネイティブな取引ルートを通じてより柔軟になっています。 BingX TradFiでは、ユーザーがUSDTで主要な米国株先物を取引でき、トークン化された株式は従来の証券口座なしに株価エクスポージャーを得る別の方法を提供しています。このガイドでは、2026年のAI半導体サプライチェーン、最も重要な8つの株式、サイクルを推進する構造的トレンド、投資家が取引前に理解すべき主要なリスクを詳しく説明します。
2026年のAI半導体サプライチェーン:AIチップサプライチェーンの4つの層
個別のAI半導体株を見る前に、まずチップサプライチェーンをマッピングすることが役立ちます。現代のAIチップは、装置、製造・パッケージング、アーキテクチャ・IP、チップ設計という4つの主要な層に依存しています。各層は、EUVリソグラフィなどの上流のボトルネックから、GPU、ASIC、ネットワークチップ設計者間の下流競争まで、AIハードウェアサイクルにおいて異なる役割を担っています。
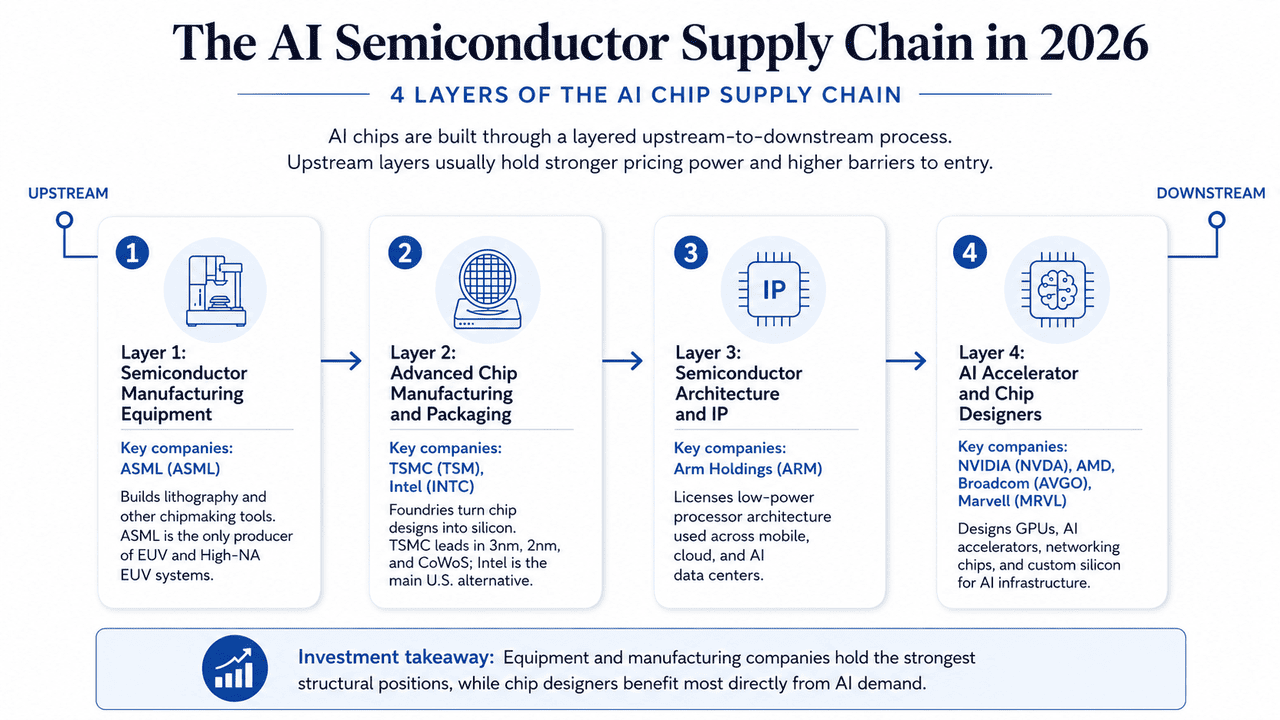
第1層:半導体製造装置
主要企業:ASML(ASML)
先端チップ生産は、半導体製造を可能にする機械から始まります。装置サプライヤーは、リソグラフィ、蒸着、エッチング、計測システムを提供し、チップサプライチェーンの中で最も技術的に要求が高く、集中度の高い部分の一つとなっています。ASMLは、先端チップ生産に必要なEUVおよび高NAのEUVリソグラフィシステムの唯一の生産者であるため、この層の主要企業です。これらの機械は、3nm未満のプロセスノードでの先端AIアクセラレータ製造に不可欠です。
第2層:先端チップ製造・パッケージング
主要企業:TSMC(TSM)、Intel(INTC)
チップが設計されると、ファウンドリは先端プロセスノードとパッケージング技術を使用して、その設計図を物理的なシリコンに変換します。製造歩留まり、プロセスリーダーシップ、パッケージング能力がすべて、AIチップを大規模に生産できるかどうかを決定します。TSMCは、3nm生産、2nmの立ち上げ、CoWoS先端パッケージングを含む先端製造のリーダーであり続けています。Intelは、18Aおよび将来の14Aプロセスロードマップを通じて、主要な米国ベースの代替案になることを目指しています。
第3層:半導体アーキテクチャ・IP
主要企業:Arm Holdings(ARM)
チップ設計者が最終製品を構築する前に、多くはライセンスされたプロセッサアーキテクチャと半導体IPに依存しています。これらのビジネスは直接チップを製造しません。代わりに、そのアーキテクチャが異なるエンドマーケットで採用されるにつれて、ライセンスおよびロイヤリティ収入を得ています。Armは、スマートフォン、組み込みデバイス、 クラウドインフラ、そして次第にAIデータセンターで使用される低電力プロセッサアーキテクチャを持つ、この層の主要企業です。AWS、 Google、 MicrosoftからのカスタムチップはすべてArmベースの設計に依存しています。
第4層:AIアクセラレータ・チップ設計者
主要企業:NVIDIA(NVDA)、Advanced Micro Devices(AMD)、Broadcom(AVGO)、Marvell Technology(MRVL)
サプライチェーンの下流端では、ファブレス企業が現代のAIインフラを支えるAIアクセラレータ、GPU、ネットワークチップ、カスタムシリコンを設計しています。これらの企業は、TSMCなどのファウンドリに製造を外注し、性能、ソフトウェアエコシステム、効率性、顧客採用で競争しています。NVIDIAは、Hopper、Blackwell、将来のRubin GPUで汎用 AI計算をリードしています。AMDはMIシリーズアクセラレータとEPYC CPUを通じて競争し、Broadcomはハイパースケーラーのカスタムチップに注力し、Marvellは大規模AIクラスター向けのネットワーキングと光学相互接続ソリューションを提供しています。
2026年のAI半導体サプライチェーントレンド:推論、HBM、先端パッケージング
2026年、AI半導体サプライチェーン全体で価格決定力と長期価値が蓄積される場所を再形成するいくつかの構造的変化があります。
1. AI推論需要がトレーニングを上回っている
エージェンティックAIシステム、推論モデル、エンタープライズAIアプリケーションが世界規模で拡大するにつれて、AIインフラ需要はトレーニングよりも推論によってますます推進されています。これにより、業界の焦点は生の計算性能から性能/ワット比とコスト/トークン効率にシフトし、Vera Rubin AIプラットフォームを準備するNVIDIAなどの企業に利益をもたらしています。
2. ハイバンド幅メモリ(HBM)がボトルネックとなった
HBMは、 Micron Technology、SK hynix、Samsung Electronicsに生産が集中し、AIハードウェアスタックの中で最も供給制約のある部品の一つになりました。供給のタイト化とAIアクセラレータ需要の急増により、メモリは循環的な商品ビジネスから高マージンな価格決定力のある分野に変わりました。
3. 先端パッケージングがプロセスノードと同じく重要になっている
トランジスタスケーリングがより困難になるにつれて、CoWoS、チップレット、3Dスタッキングなどの先端パッケージング技術がAIアクセラレータの重要な性能ボトルネックになっています。TSMCの先端パッケージング能力での優位性は、AIサプライチェーン全体で大きな競争優位性となっています。
4. ハイパースケーラーがより多くのカスタムAIチップを構築している
Google、 Meta、 Amazon、Microsoftなどの大手クラウド企業は、汎用GPUに完全に依存するのではなく、特定の推論ワークロードに最適化されたカスタムAIアクセラレータをますます設計しています。この傾向は、カスタムAIシリコンのBroadcomとネットワーキングおよび光学相互接続インフラのMarvell Technologyに大きな利益をもたらしています。
2026年に注目すべきトップ8のAI半導体株とは?
以下の企業は、装置から始まって製造、アーキテクチャ、チップ設計を通じて下流に移動する、AI半導体サプライチェーンでの位置によって整理されています。この構造は重要です。なぜなら、上流の層は一般的により強い価格決定力、より高い参入障壁、より持続可能な競争優位性を持っているからです。8社すべてがBingX TradFiのUSDTマージン株式先物を通じてアクセス可能です。
1. ASML Holding(ASML)
中核的役割:EUVおよび高NA EUVリソグラフィ独占
サプライチェーン層:第1層 - 半導体製造装置
ASMLは、半導体サプライチェーンの最も構造的に強力なポイントに位置しています。同社は、3nmノード以下の先端AIチップ製造に必要なEUVリソグラフィシステムの世界唯一の生産者です。次世代プロセスノードに不可欠な高NA EUVシステムは、現在1台あたり数億ユーロの費用がかかり、ASMLの価格決定力と技術的な堀を強化しています。
需要は、AIインフラ容量の拡大を競うファウンドリとメモリメーカーによって推進され続けています。同社は、2026年第1四半期に53%の粗利益率で88億ユーロの収益を報告し、通年ガイダンスを360~400億ユーロに引き上げました。中国に影響する地政学的輸出制限にもかかわらず、ASMLは2025年末に380億ユーロを超えるバックログで終了し、TSMC、Samsung、SK hynixなどの顧客からの長期需要に支えられています。
詳細: ASML Holding(ASML)株価予想2026年:AIインフラの王者か地政学的標的か?
2. Taiwan Semiconductor Manufacturing(TSM)
中核的役割:純粋ファウンドリと先端パッケージングリーダー
サプライチェーン層:第2層 - 先端製造・パッケージング
TSMCは、世界のAI業界の製造バックボーンです。同社は、NVIDIA、AMD、 Apple、Broadcom、ほとんどの主要半導体設計者向けのチップを物理的に製造しています。3nm量産、2nmの立ち上げ、将来のA16ノードを含む先端ノードでの優位性により、AIチップ生産においてほぼ代替不可能な役割を持っています。
TSMCの優位性は、もはやウエハー製造に限定されません。CoWoS先端パッケージング能力は、すべての最先端AIアクセラレータがそれに依存しているため、業界で最も重要なボトルネックの一つになっています。2026年、TSMCは、AI駆動のHPC需要が同社史上初めてスマートフォンを上回り最大の収益セグメントになったため、通年収益成長ガイダンスを30%以上に引き上げました。
詳細: TSMC(TSM)価格予想2026年:480ドルでのAI独占か地政学的罠か?
3. Intel(INTC)
中核的役割:統合デバイスメーカーおよび米国ファウンドリ代替
サプライチェーン層:第2層 - 先端製造・パッケージング
Intelは、AI半導体サプライチェーンで最も議論の分かれるターンアラウンドストーリーです。CEO Lip-Bu Tanの下で、同社は18Aノードを中心にファウンドリロードマップを安定化させ、高NA EUVを使用する将来の14Aプロセスは、外部のカスタムチップ顧客向けに位置付けられています。戦略的なケースは、IntelがTSMCに対する唯一の信頼できる米国ベースの最先端ファウンドリ代替案であり続けることです。
2026年第1四半期の決算は強気のケースを大幅に改善しました。収益は前年同期比7.18%増の135.8億ドルに達し、データセンター・AI収益は22%増の50.5億ドルとなりました。Intelにはまだ実行リスクがありますが、CHIPS法支援、防衛関連需要、サプライチェーン多様化により、同社はほとんどのファブレスチップ設計者とは異なる政治的・戦略的重要性を持っています。
詳細: Intel(INTC)株式予想2026年:89ドルへのファウンドリブレークスルーか価値の罠か?
4. Arm Holdings(ARM)
中核的役割:エネルギー効率的なプロセッサアーキテクチャライセンシング
サプライチェーン層:第3層 - 半導体アーキテクチャ・IP
Armは、現代のチップ業界の多くが構築するプロセッサアーキテクチャを提供しています。同社は直接チップを製造せず、設計図をライセンスしています。AI時代にデータセンターの電力制約がより重要になるにつれて、Armのエネルギー効率的な設計は、クラウドCPUとカスタムシリコンの両方でますます関連性が高まっています。
AWS Graviton、Google Axion、Microsoft Cobaltなどの主要なハイパースケーラーチップはすべてArmアーキテクチャ上に構築されています。これにより、Armは業界全体のチップ出荷に応じてスケールするロイヤリティ駆動モデルを持っています。投資家が推論ピボットとカスタムCPUトレンドをArmの長期ロイヤリティ機会に結び付けたため、株式は2026年4月だけで約39%急騰しました。
詳細: Arm Holdings(ARM)株式見通し2026年:AIライセンシングと200ドル以上の価格目標
5. NVIDIA(NVDA)
中核的役割:GPU設計とCUDAソフトウェアエコシステム
サプライチェーン層:第4層 - AIアクセラレータ・チップ設計
NVIDIAは、AIインフラスタックの中心であり続けています。そのGPUは最前線のトレーニングワークロードの大部分と推論の成長する部分を支えており、CUDAは競合他社が破ることに苦労してきたソフトウェアの堀であり続けています。NVIDIAの優位性は、チップ性能だけでなく、そのハードウェア周辺に構築された開発者エコシステム、ライブラリ、フレームワーク、プラットフォーム依存性でもあります。
FY2027第1四半期の結果は論理を補強し、収益は816億ドル、調整後EPSは1.87ドルに達し、予想を上回りました。次の主要な触媒は、2026年後半に予想されるVera Rubinプラットフォームで、経営陣はそのライフサイクル全体を通じて供給制約が続くと述べています。NVIDIAの時価総額は現在、ハードウェアサプライヤーと現代のAI計算の動作層両方としての役割を反映しています。
オンチェーン投資家は、NVIDIAのトークン化株式のように完全に裏付けされたNVDAON(Ondo Finance)やNVDAX SolanaベースのxStockを通じて直接この価格動向を追跡しています。
詳細: Nvidia(NVDA)2026年株価見通し:BlackwellとVera RubinはNVDAを300ドルに戻せるか?
6. Advanced Micro Devices(AMD)
中核的役割:ファブレスGPU・CPU設計
サプライチェーン層:第4層 - AIアクセラレータ・チップ設計
AMDは、AIアクセラレータにおけるNVIDIAの主要な商業的代替案です。その機会は、顧客が総所有コスト、供給多様化、単一GPUベンダーへの依存削減を重視する場所で最も強いです。MIシリーズアクセラレータロードマップとEPYCサーバーCPUフランチャイズにより、AMDはAI計算とより広いデータセンターインフラサイクルの両方への露出を得ています。
2026年第1四半期の収益は前年同期比38%増の103億ドルに達し、データセンター収益は57%急増して58億ドルとなりました。MetaがMI450アクセラレータプラットフォームを中心とした複数年展開契約を発表した後、AMDのAI勢いは加速しました。経営陣はまた、エージェンティックAIワークロードが展開されるアクセラレータあたりのCPU要件を増加させるため、2026年にサーバーCPU収益が70%以上成長すると予想しています。
詳細: AMD価格予想2026年:525ドルのAI主権か300ドルの評価の罠か?
7. Broadcom(AVGO)
中核的役割:カスタムAIアクセラレータと高速ネットワーキングシリコン
サプライチェーン層:第4層 - AIアクセラレータ・チップ設計
Broadcomは、カスタムシリコン論理の最強の純粋な表現です。汎用GPUでNVIDIAと直接競争する代わりに、BroadcomはGoogleのTPUプログラムやAnthropicなどの企業との主要なカスタムAI展開を含む、ハイパースケーラー向けのアプリケーション固有AIアクセラレータを共同設計しています。これにより、Broadcomは汎用計算からワークロード固有の推論ハードウェアへのシフトの中心に位置しています。
財務的証拠はすでに見えています。FY2026第1四半期のAI半導体収益は前年同期比106%増の84億ドルに達し、経営陣は第2四半期のAI収益を107億ドルとガイドしました。Broadcomの730億ドルのAI特化バックログは、2027年に1,000億ドル以上のAIチップ収益への経営陣の道筋に信頼性を与えています。
詳細: Broadcom(AVGO)2026年株式見通し:AIインフラの王者かマージンの被害者か?
8. Marvell Technology(MRVL)
中核的役割:電気光学とカスタムデータセンターシリコン
サプライチェーン層:第4層 - AIアクセラレータ・チップ設計
Marvellは、AIデータセンターで最も見えにくいが最も重要な制約の一つである、数千のアクセラレータ間でのデータ移動に対処しています。クラスターが銅ネットワーキングが効率的にサポートできる範囲を超えてスケールするにつれて、光学相互接続と電気光学が重要になります。Marvellのポートフォリオは、この接続性ボトルネック周辺に直接位置付けられています。
強気のケースは、AIデータセンター容量の新しいギガワットごとに、クラスター内にどのアクセラレータが入っているかに関係なく、Marvellクラスのネットワーキングと相互接続インフラが必要だということです。同社はまだより循環的なストレージと消費者ネットワーキング市場への露出を持っていますが、投資家はますます電気光学パイプライン、カスタムASICプログラム、次世代AIクラスター接続での役割に注目しています。
詳細: Marvell(MRVL)2026年見通し:AI&シリコンモメンタムは株価を150ドルに押し上げられるか?
サプライチェーンポジション別2026年AI半導体株比較
AI半導体株は、装置・製造からアーキテクチャ・チップ設計まで、チップサプライチェーンの異なる部分に位置しています。この比較は、各企業が構造的ボトルネック、AI需要成長、長期価格決定力からどのように利益を得るかを示しています。
|
サプライチェーン層 |
ティッカー |
中核優位性 |
2026年触媒 |
|
装置 |
ASML |
EUVおよび高NA EUVリソグラフィシステムの唯一の供給者 |
2026年収益ガイダンスを360~400億ユーロに引き上げ;EUV需要は構造的に強い状態が続く |
|
製造 |
TSM |
最先端ファウンドリとCoWoS先端パッケージングリーダー |
AI/HPC需要加速により通年収益成長ガイダンスを30%以上に引き上げ |
|
製造 |
INTC |
18A/14Aロードマップを持つ米国ベースの先端ファウンドリ代替 |
2026年第1四半期結果が予想を上回る;14Aが外部AIチップ顧客向けに位置付けられる |
|
アーキテクチャ・IP |
ARM |
ハイパースケーラーカスタムチップを支えるエネルギー効率的CPUアーキテクチャ |
AIロイヤリティのステップアップとハイパースケーラーCPU採用がマージン拡大を支援 |
|
チップ設計 |
NVDA |
CUDAエコシステムロックインと最先端AIGPUプラットフォーム |
FY2027第1四半期が予想上回る;Vera Rubinの立ち上げが2026年後半に予想 |
|
チップ設計 |
AMD |
MIシリーズAIアクセラレータとEPYCサーバーCPUフランチャイズ |
Meta 6GW展開契約;第2四半期収益ガイドを112億ドルに引き上げ |
|
チップ設計 |
AVGO |
ハイパースケーラーカスタムAI ASICとネットワーキングシリコン |
AI半導体収益が前年同期比106%増;FY2027までに1,000億ドルのAI収益ランレートへの道筋 |
|
チップ設計 |
MRVL |
AIクラスター向け光学相互接続とカスタムデータセンターシリコン |
電気光学とASICパイプラインが次のデータセンター成長フェーズを推進すると予想 |
BingXでAI半導体株を取引する方法
BingXは、従来の証券口座なしにこれらの銘柄への露出を得る2つの明確な経路を提供しています。 トークン化株式は現物市場で基礎株式を1:1の経済ベースで追跡し、 BingX TradFiのUSDTマージン無期限契約は24時間体制で価格変動にレバレッジをかけた露出を提供します。
BingX現物でAI半導体トークン化株式を購入、売却、またはHODL
レバレッジなしで直接的な株価露出を求める長期投資家向けに、 BingX現物市場は、Backed Financeや Ondo Financeなどの規制された資産フレームワークを通じて発行された完全に裏付けされたトークン化株式へのアクセスを提供します。これらのデジタル資産は、実世界の株価を1:1の経済ベースで追跡するように設計されており、USDTなどのステーブルコインで直接取引できます。
ステップ1:アカウント設定とセキュリティ。 新規登録してBingXアカウントにログインし、お住まいの地域で必要な本人確認(KYC)を完了し、 2段階認証を有効にします。
ステップ2:現物ウォレットに資金を入金。TRC-20、ERC-20、または Arbitrumなどの一般的な選択肢を使用して、お好みのネットワークを使用して USDTを入金します。送金前に最低入金額とネットワーク手数料を確認してください。
ステップ3:現物市場に移動。完全に裏付けされた、レバレッジなしの露出のために、 NVDAON/USDTや NVDAX/USDTなどのトークン化株式ペアを検索します。
ステップ4:BingX AIアナリストを使用。埋め込まれた BingX AIツールは、エントリーを改善するために、 サポート・レジスタンスレベル、 移動平均、ボラティリティ指標をチャート上で直接表示します。
ステップ5:実行と決済。 成行または指値注文を選択し、USDT金額を入力して確認します。トークン化株式残高は約定時に現物ウォレットに即座に反映されます。
BingX TradFiでUSDTでAI半導体株式先物を取引
短期的な市場モメンタム、決算ボラティリティ、またはヘッジ戦略を活用しようとするアクティブトレーダー向けに、 BingX TradFiでは、ユーザーがUSDTで主要な米国株先物を取引できます。これらのUSDT決済無期限契約は、基礎株式の価格変動を反映し、物理的な株式やトークン化資産を保有することなく、柔軟なロングおよびショート露出を提供します。
ステップ1:BingX TradFiインターフェースにアクセス。 新規登録してログインし、 TradFi市場ページまたは 先物取引セクションに移動します。
ステップ2:資本配分。現物ウォレットから先物アカウントにUSDTを移行し、担保として機能させます。
ステップ3:契約を選択。株式連動無期限契約のラインナップから選択します。例: ASML-USDT、 TSMU-USDT、 INTC-USDT、 ARM-USDT、 NVDA-USDT、 AMD-USDT、 AVGO-USDT、または MRVL-USDT。
ステップ4:方向とレバレッジを設定。株式の上昇を予想する場合は ロング注文を開き、下落から利益を得るためにショートを開きます。リスク計画に応じてレバレッジを選択します。
ステップ5:実行とリスク管理。取引を提出する前に厳格な 損切りと利確注文を設定します。 損益はUSDTで動的に決済されます。
半導体株取引時のリスクと主な考慮事項
半導体株は、AIインフラサイクルへの強い露出を提供しますが、評価、設備投資期待、地政学、ボラティリティに関連する意義あるリスクも抱えています。
- 評価圧縮リスク:多くのAI半導体株は、プレミアム先行倍率で取引されています。ハイパースケーラーの支出が鈍化したり、収益ガイダンスが弱くなったりすると、これらの銘柄は急激に再価格設定される可能性があります。
- 半導体サイクルリスク:メモリ、ファウンドリ容量、装置需要は循環的なままです。企業が過度に積極的に拡大したり、クラウド顧客が新規注文を延期したりすると、供給過剰が発生する可能性があります。
- 地政学的集中リスク:最先端チップ製造は依然として台湾に大きく集中しており、装置供給は輸出規制と貿易政策の変更に露出しています。これはTSMやASMLなどの銘柄に圧力をかける可能性があります。
- レバレッジと清算リスク:株式先物は利益と損失の両方を拡大します。トレーダーは、特に決算やAI設備投資ニュース周辺で、ポジションサイズを慎重に管理し、損切り注文を使用する必要があります。
- トークン化株式の制限:トークン化された株式は株価パフォーマンスを追跡しますが、議決権、配当権利、または物理的株式の配達を提供しない場合があります。
最終考察:2026年のポートフォリオに半導体株を追加すべきか?
2026年の半導体サイクルは、強いバランスシートを持つハイパースケーラーからの実際のAIインフラ支出によって需要が推進されているため、以前のチップブームとは異なります。NVIDIAのCUDAエコシステム、TSMCのファウンドリ・CoWoSリーダーシップ、ASMLのEUVリソグラフィ独占、BroadcomのカスタムAI ASICパイプラインは、それぞれAIハードウェアスタックの異なるボトルネックを表しています。投資家にとって、設計、製造、装置、IPを横断する分散投資は、単一企業の実行に過度に依存することなく、AIチップサイクルへのより幅広い露出を提供できます。
しかし、このセクターはすでにプレミアム評価で取引されており、ハイパースケーラーの設備投資計画、収益ガイダンス、AIインフラ支出トレンドに高い感度を維持しています。長期投資家はポジションサイジングと分散投資に焦点を当てるべきで、BingX TradFiを使用するアクティブトレーダーは、損切りと利確コントロールでレバレッジを慎重に管理すべきです。トークン化された現物露出やUSDTマージン無期限契約を通じて、AI半導体株は暗号資産ネイティブな取引ルートを通じて世界の投資家にとってよりアクセスしやすくなりました。